From Siloed Operations to
Unified Agentic Operations
AI Agents to Break Silos: Need Unified Control Plane & Agentic Data Federation
Pulished: February 27th, 2026

Raju Datla
CEO, Fabrix.ai
Enterprise IT and SRE operations today are deeply fragmented. Most organizations operate more than twenty monitoring and observability tools spanning cloud-native applications, traditional enterprise systems, infrastructure, networks, and security. Each platform focuses on a specific domain - APM, NPM, SIEM, cloud, or infrastructure, forcing operations teams to manually swivel between dashboards to correlate signals and determine root cause. This “swivel chair” problem slows incident response, increases operational complexity, and prevents true automation. As enterprises move toward autonomous operations, this siloed approach is no longer sufficient.
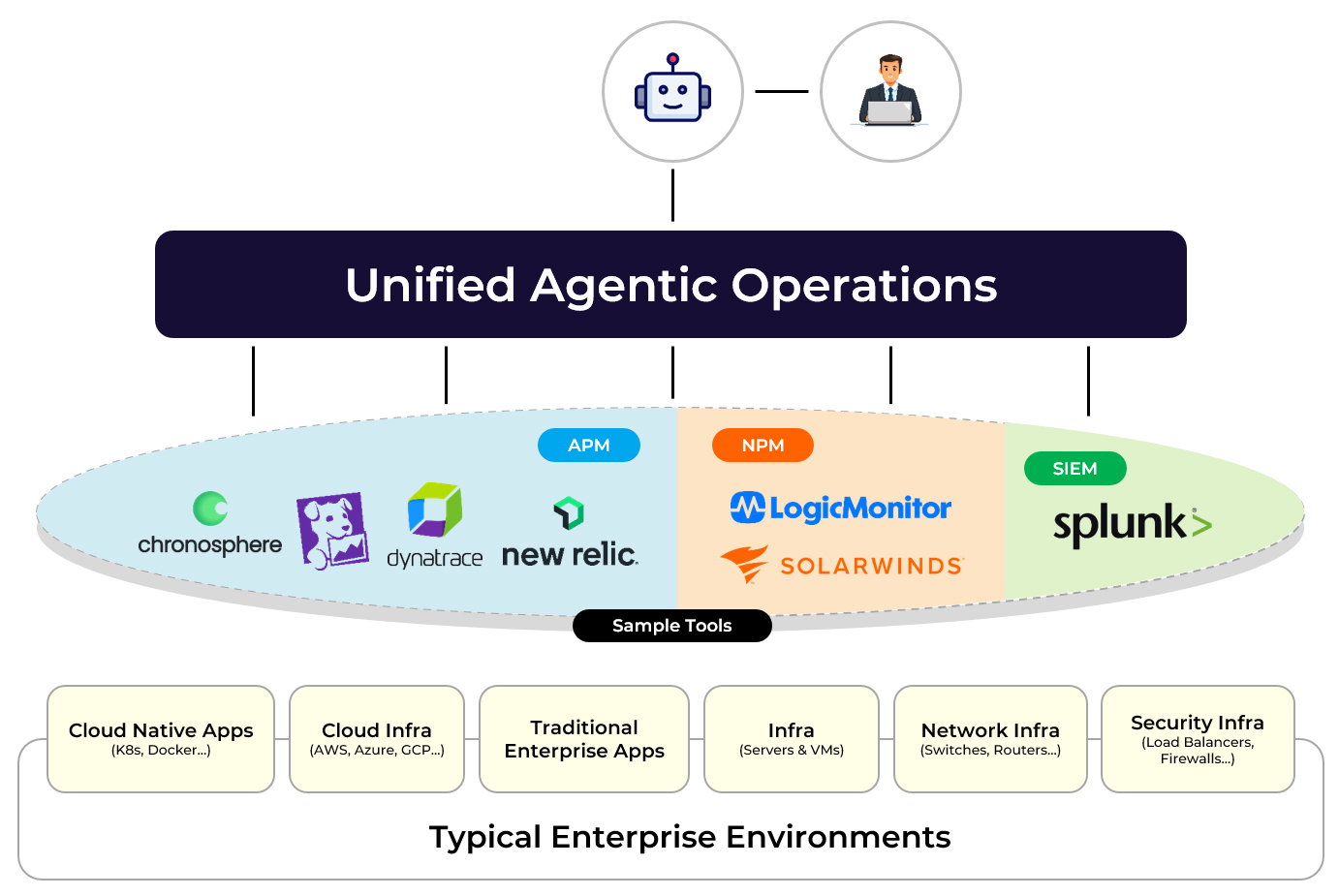
Siloed Approach (Siloed Operations to Siloed Agentic Operations):
The Swivel Chair problem: SREs and IT Ops teams jump between dashboards, alerts, and consoles trying to correlate signals manually. Root cause analysis becomes a human stitching exercise across siloed systems. Mean time to resolution increases. Productivity declines. Automation stalls.
In response, many observability vendors have introduced AI agents. However, in most cases these agents are simply layered on top of existing siloed platforms. The underlying architecture remains unchanged. Each vendor’s agent operates within its own ecosystem, without the ability to reason across domains or orchestrate multi-vendor workflows. The result is not unified operations, it is siloed intelligence.
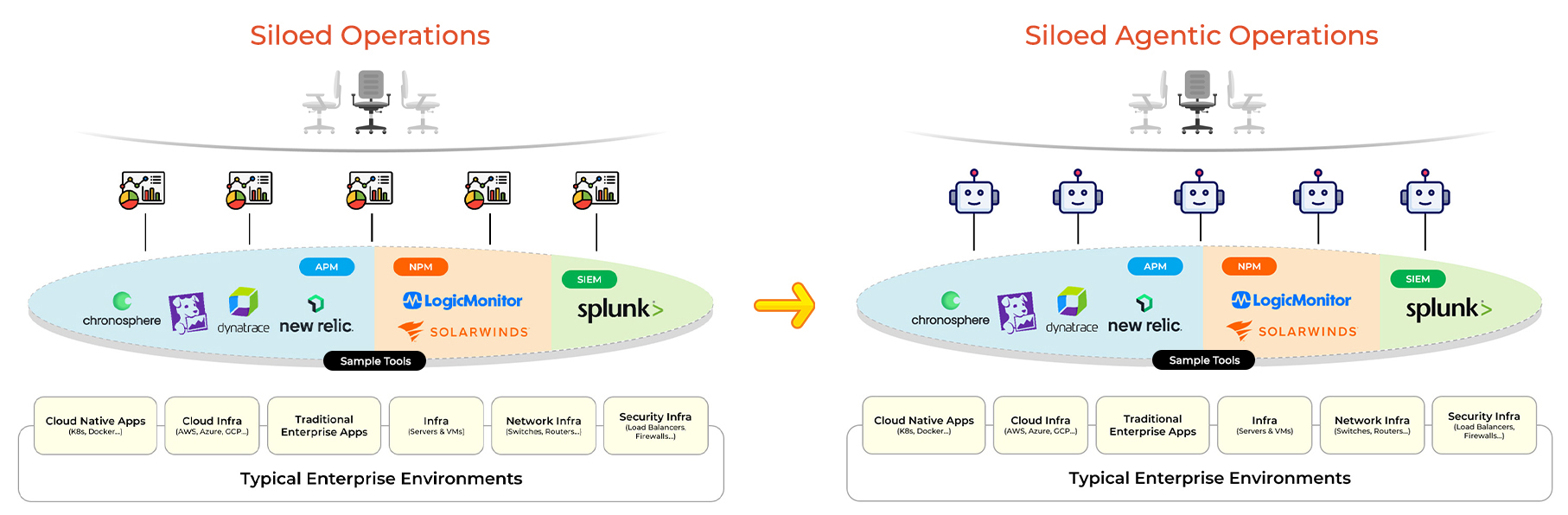
Desired Approach by Enterprise Leaders
What enterprises actually want is end-to-end, unified agentic operations. They expect AI agents to seamlessly connect cloud, infrastructure, network, and security systems, correlate signals across domains, and drive faster root cause analysis and remediation. The goal is not another layer of dashboards, but autonomous execution across the entire IT estate.
- One AI touch point, not dealing with too many tools
- Unified Control Plane
- Federate across data silos
- Orchestrate across multiple agents
Typical Approaches:
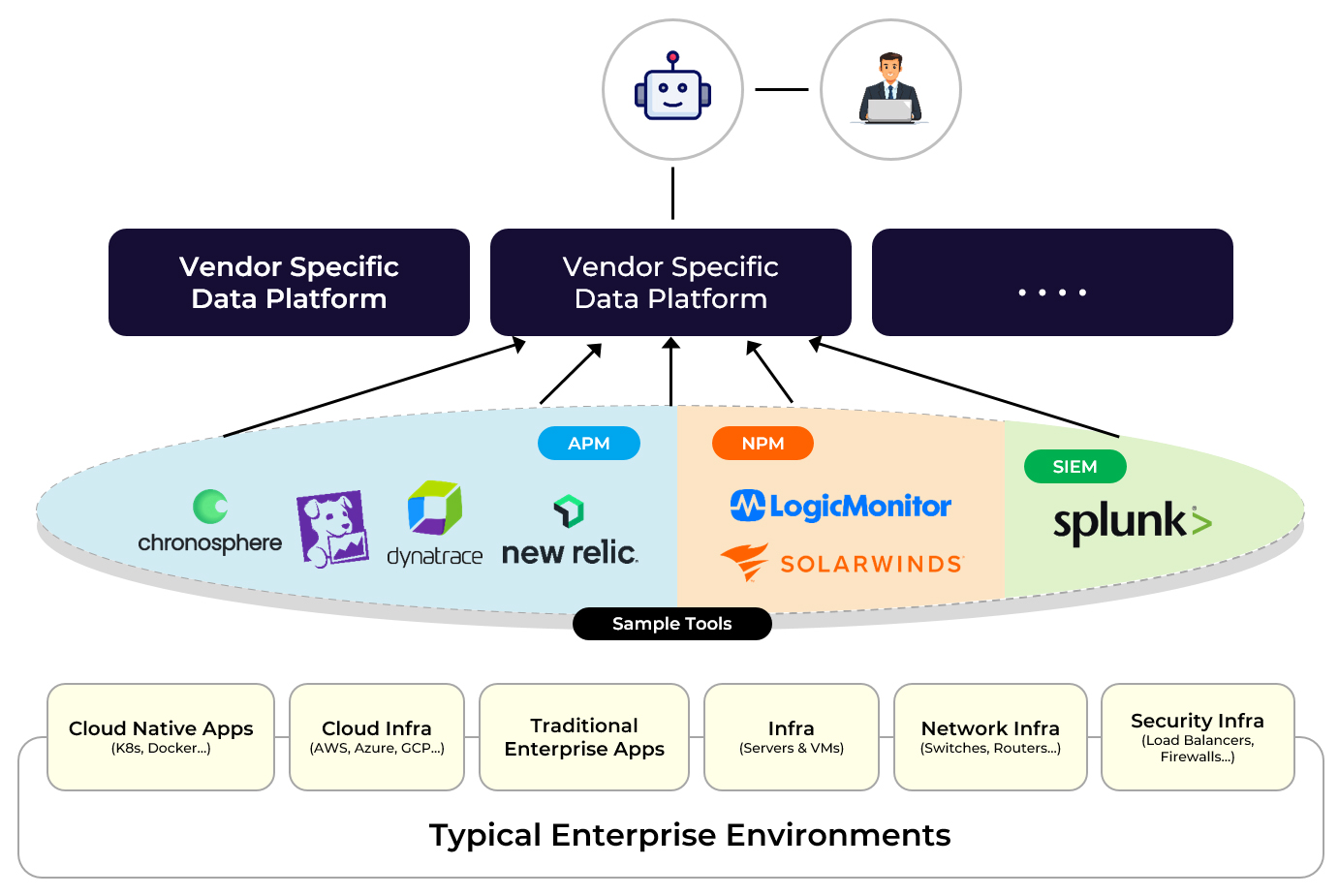
Centralization Trap
Some vendors attempt to solve this by asking enterprises to re-ingest all operational data into a single centralized platform. In practice, this approach is expensive and disruptive. It requires architectural redesign, increases data storage and processing costs, and still does not inherently deliver automation or auto-remediation. Centralization adds cost without eliminating silos.
Re-ingest back to one platform.
- Limited support for data ingestion
- Architectural redesign
- Significant increase in data costs
"Send Us All the Data" - Significant Architectural Impact
Other approaches fall short
- Manual federation is not scalable: Mapping data schemas across multiple tools and domains requires ongoing customization, brittle integrations, and constant maintenance, slowing time to value.
- Cloud native only focus is incomplete: Vendors built solely around OpenTelemetry and cloud-native stacks ignore the majority of enterprise workloads(75%+) that still run on traditional infrastructure.
Fabrix Approach
Unified Agentic Operations: Cross-domain & Multi-Vendor
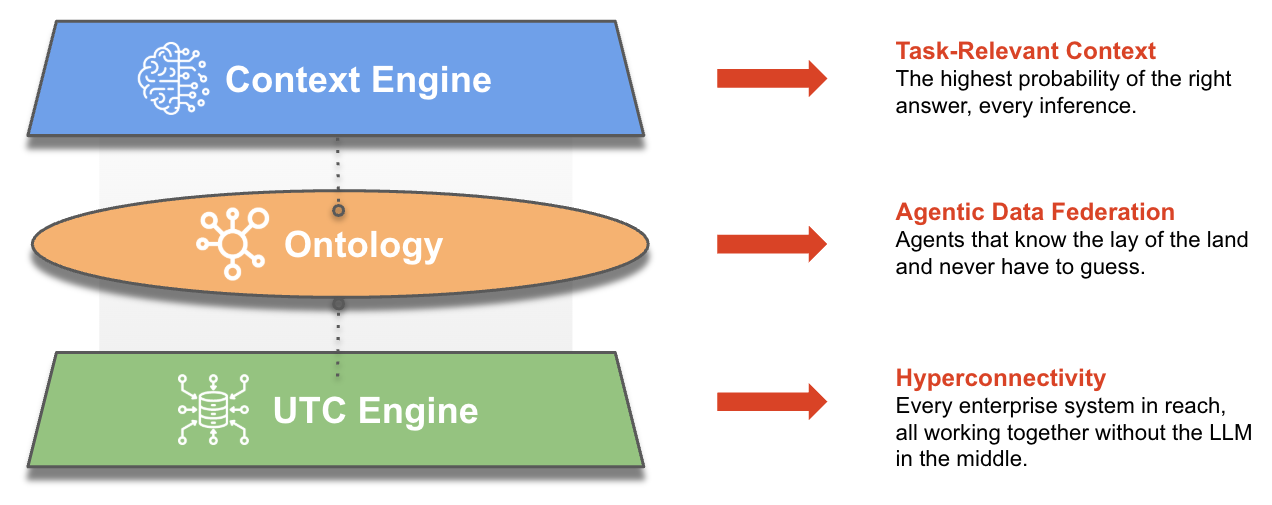
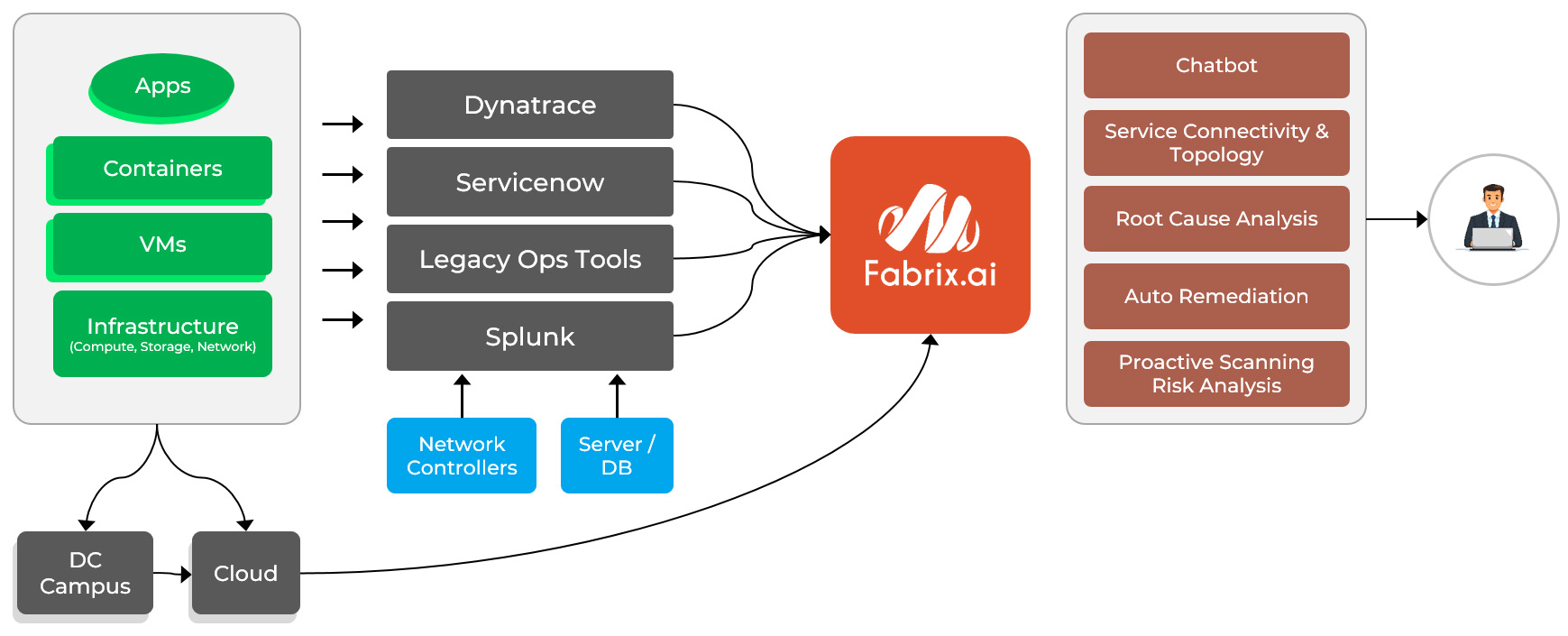
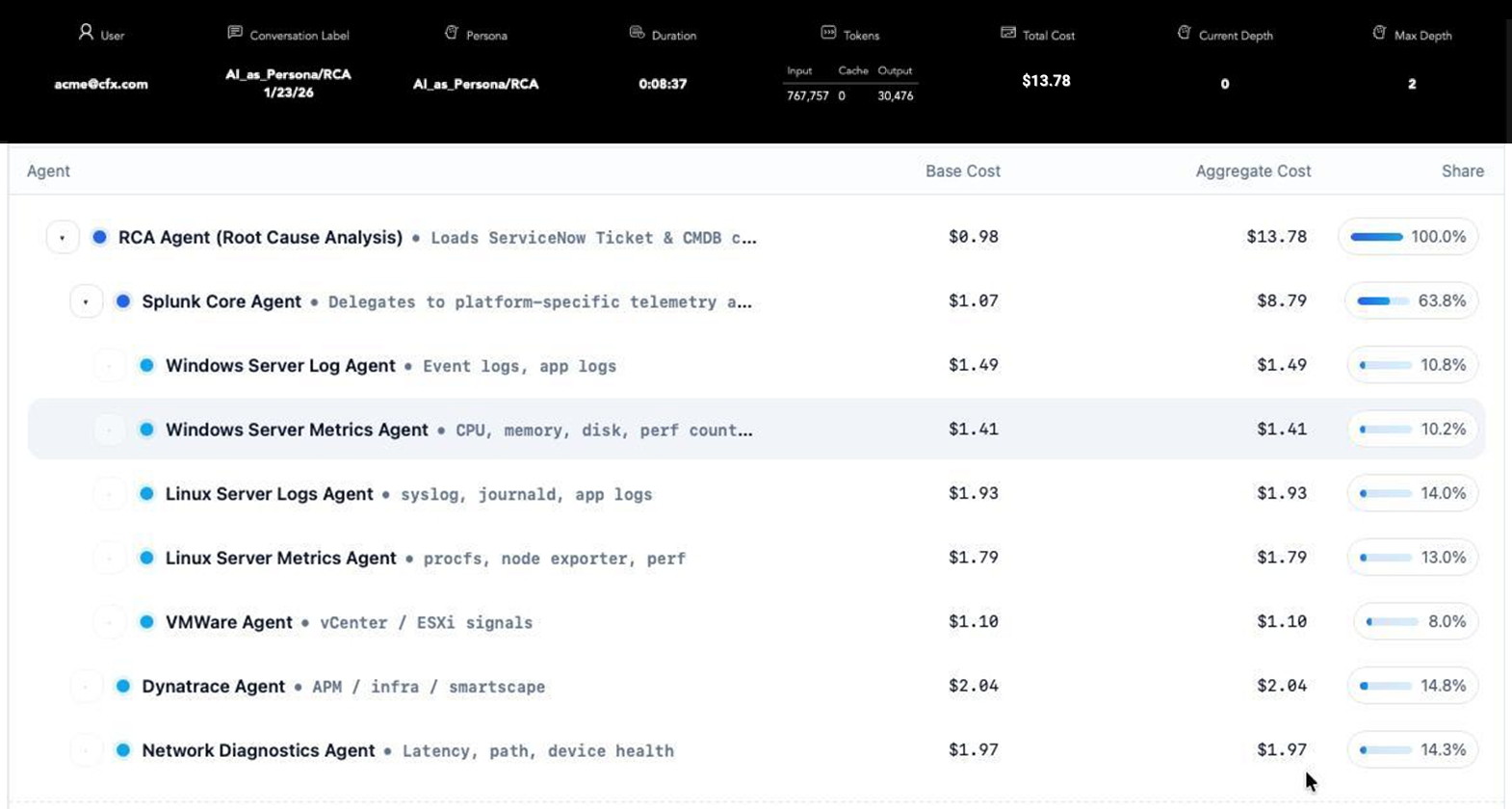
Fabrix takes a fundamentally different approach through Agentic Data Federation powered by ontology and orchestration. Instead of moving data, Fabrix keeps data where it resides and deploys federation agents across existing observability platforms. By building a cross-domain enterprise ontology and orchestrating workflows across vendors, Fabrix enables automated remediation without forcing enterprises to re-architect their environments. This creates true unified agentic operations, not bolt-on intelligence, but coordinated, cross-domain autonomy.
The future of IT operations is not siloed monitoring or centralized data lakes. It is federated, cross-domain, autonomous operations. That is the shift enterprises are demanding and the shift Fabrix is delivering.
- Why enterprise needs different architecture: Production blueprint for addressing 16 production challenges
Unified Agentic Operations: Unified Control Plane &
Agentic Data Federation
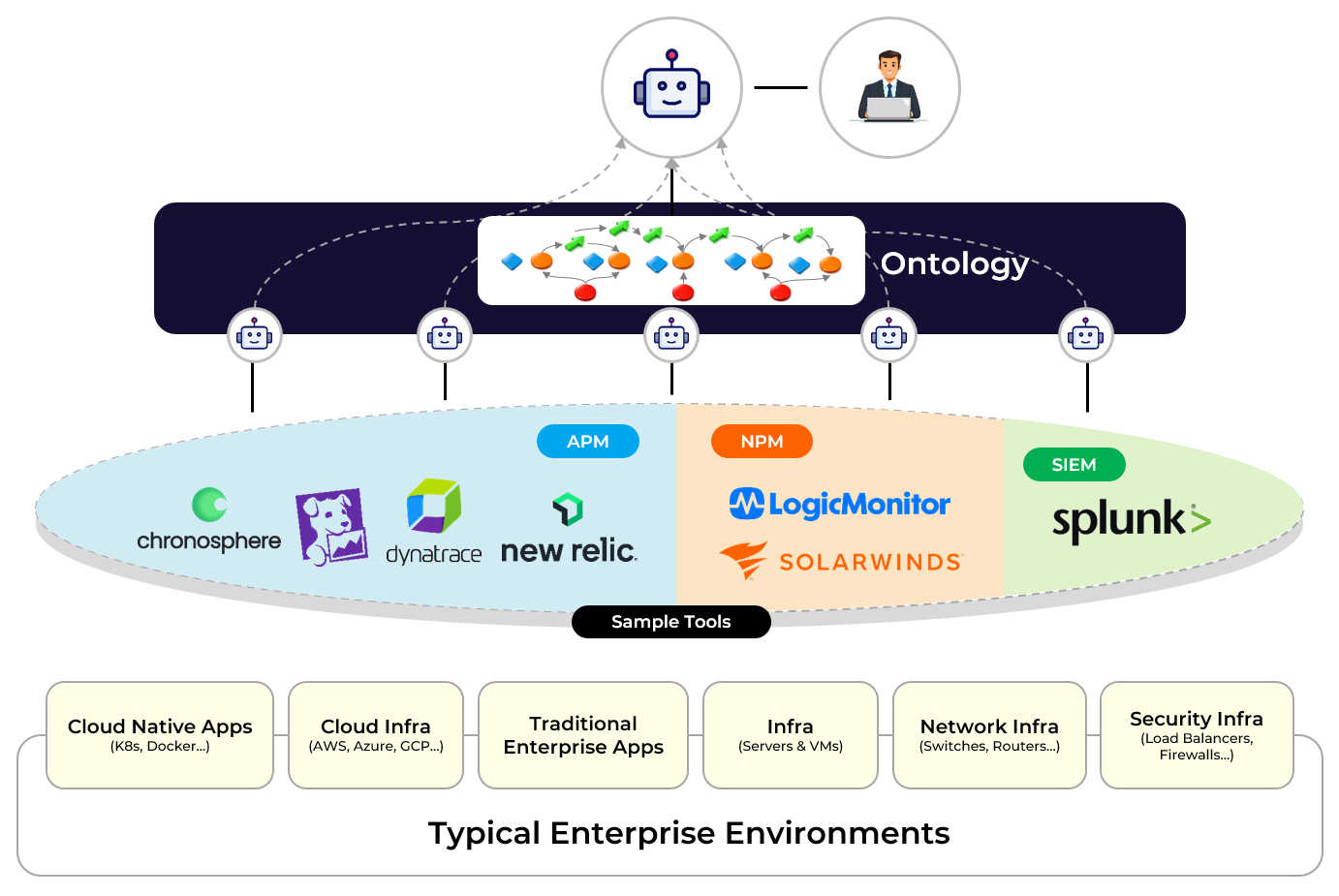
Three Layers, Working Together