Data Fabric
Unifies all data sources, structured and unstructured in real time
Data Fabric
for Modern Autonomous Operations
Unlock the full potential of your IT data with our Data Fabric, designed to ingest, enrich, transform, and route data at scale across any stack and environment.
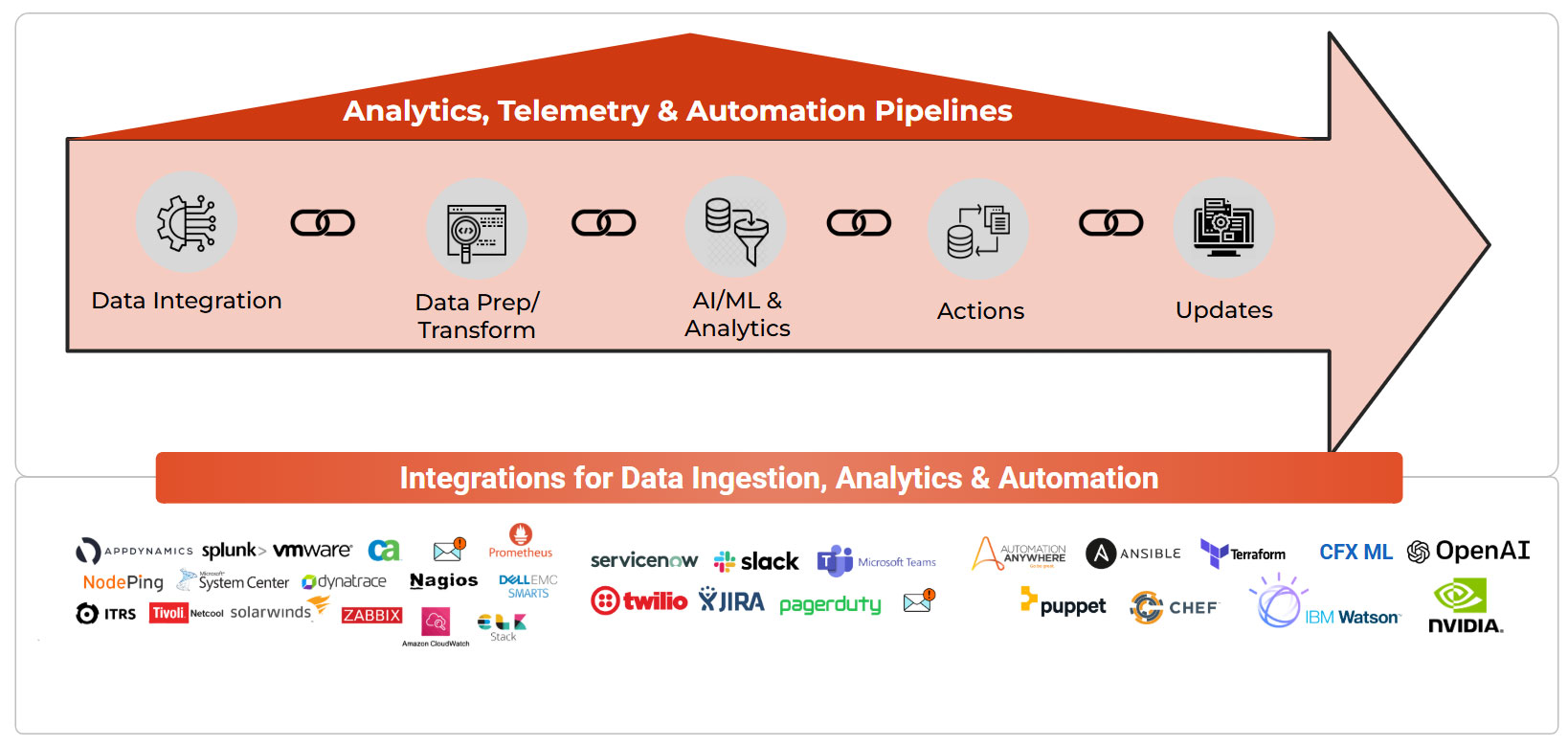
1900+ Data Bot Library
Automate data processing activities using pre-built bots that perform API operations, data operations – like filtering, aggregating, enriching or routing data. Automate ML model training or inferencing. Bots work together – to help you implement telemetry and observability pipelines.
- Bots automate API requests, data operations or task
- 1900+ data bots in the library. Easy to develop new bots with SDK.
- Bots work together in low-code pipelines to implement any use
- Out of the box telemetry and observability pipelines (Gartner recognized)
- Pipelines can be authored in Jupyter style studio
- Bots can run and communicate in distributed environments enabling edge analytics
- ML model training and inferencing. Gen AI bots to interact with LLMs
- Low-code bots – easy to use, Ops, citizen developer friendly
https://docs.fabrix.ai/Extensions/extensions_A_B/ https://docs.fabrix.ai/Bots/search_bots/







































Telemetry Pipelines
Craft your perfect data flow with low-code or use pre-built solution packs. Deploy freedom: on-prem, cloud or hybrid environments. AIOps studio for rapid pipeline authoring and development
- Many-to-many routing: Liberate data by separating data producers and consumers
- Conversion to Open Telemetry for any OTEL backend
- Rich set of Pipelines for various use case scenarios: Telemetry, Observability
- In-memory pipelines for inline processing & high throughput message passing
- Inference pipelines for anomaly detection, classification and more
- Event-driven pipelines for topology updates, change detection and more
- Service pipelines for always-on data ingestion and Scheduled pipelines for timed data processing
- Action pipelines to trigger automations, Alerting pipelines for ticketing
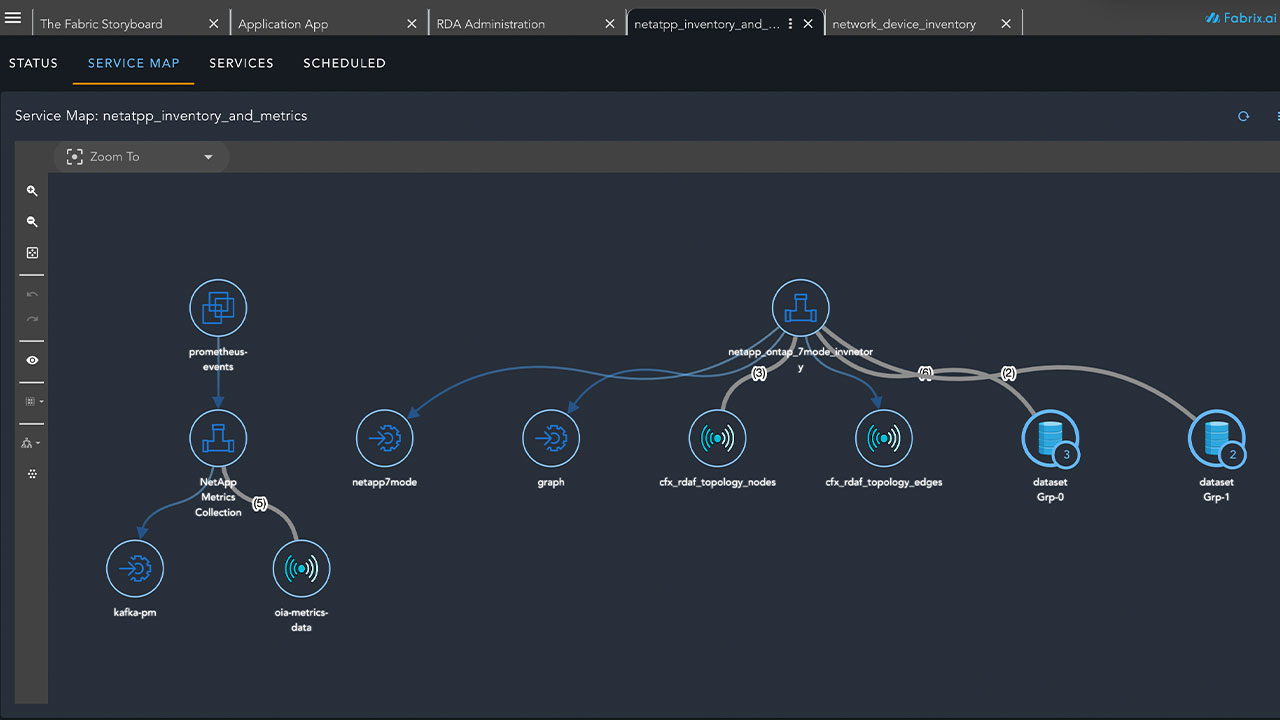
Universal Ingest

Real-time data ingestion of IT operations/service management data from devices, element managers, domain managers, object stores and data lakes. Route raw data, transformed data or compressed data to other object stores or data lakes
- Ingest many data types
- Incidents, MELT - Metrics, Event, Log, Traces, KPIs, Asset Inventory / CMDB, Topology as application dependency maps / service maps, Tickets, business specific data
- Conversion to Open Telemetry for any OTEL backend
- Agentless approach to data ingestion
- Data sources and Targets: Devices, Apps, Element managers, Domain Managers, Databases, Data lakes (Splunk, Azure ADLS etc.), Object stores (AWS S3, MinIO etc.), Message bus (Kafka, NATS), Email, Webhooks, API endpoints
- Modes: Synchronous, Asynchronous, Push/Pull, streaming telemetry, bulk/batch
- Protocols: SNMP, API, Open telemetry, Netconf/Yang, Bulkstats, gNMI, Splunk forwarders, HEC
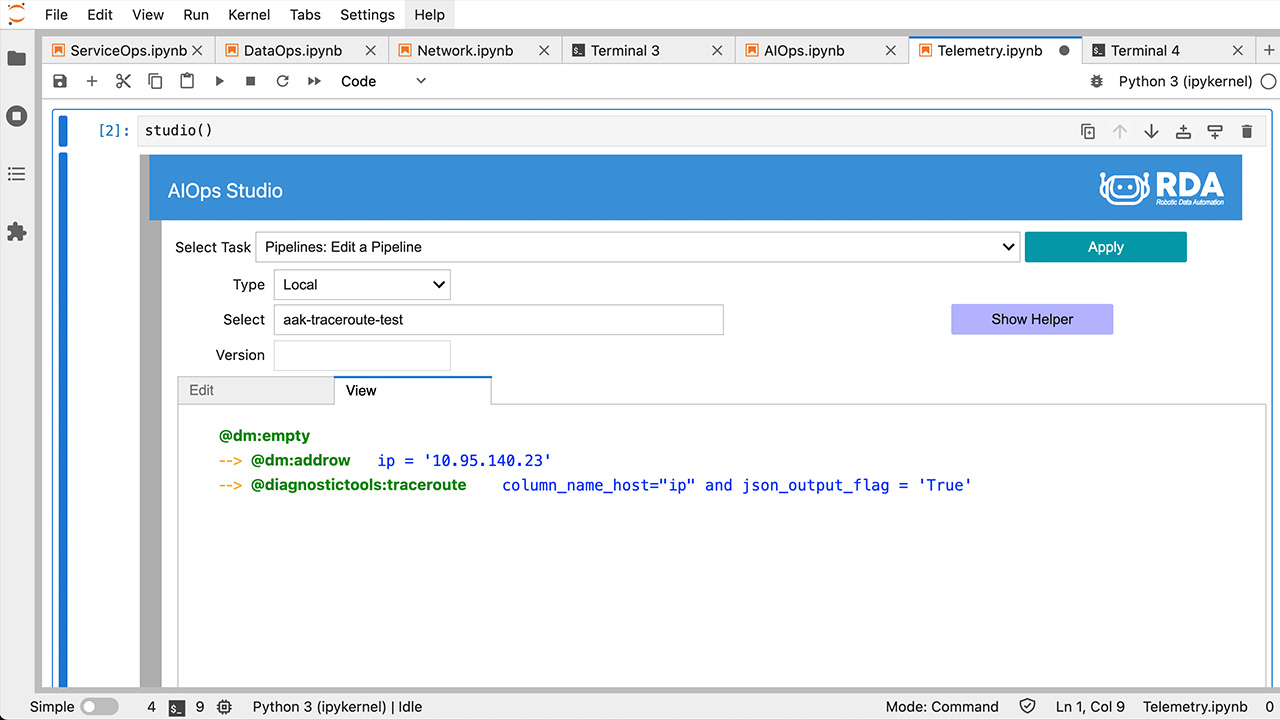
Pipeline Studio
Pipeline studio is a citizen developer friendly Jupyter-style notebook environment for authoring pipelines, testing, debugging and inspecting the pipelines, before publishing production. Pipeline studio can be installed in any VM or even developer workstations or laptops.
- Build Data Pipelines using No-Code / Low-Code interface with 1900+ bots
- Flexible Data Integration & Preparation
- Manage Pipeline Lifecycle
Data Discovery & Enrichment

Automatically build a Full-stack application dependency map (ADM), capturing physical and logical topologies using agentless discovery process, and without dependency on CMDB. Enrich raw operations data with Full-stack application or business context. Feed into key workflows like change management, root cause analysis, incident management etc.
- Automatically builds Full-stack application dependency map
- Agentless discovery approach. No dependency on CMDB
- Near real-time updates: event-driven, periodic polling or on-demand
- Enriches raw event/alert data with app/business context
- Utilize enrichment responses from third-party tools, including threat intelligence feeds (e.g., MTTRE attack), Geo IP lookups, bad IP lookups, and knowledge store queries

Liberate Data & Reduce Costs with Data Routing
- Liberate data by separating data producers and consumers
- Route to multiple locations - Cisco Observability Platform, Fabrix.ai AIOps Platform, Data Lakes, Data Lakehouse like Dynatrace Grail, Splunk, Log Stores, Analytics Platforms and Composable Dashboards
Composable Pipelines with Low-Code Bots
- Craft your perfect data flow with low-code or use pre-built solutions
- 1900+ bots in the library. Easily build new bots with SDK
- Deploy freedom: on-prem, cloud or hybrid environments.


Pipeline Choice: In-Memory, Inferencing, Event-Driven, etc.
- Rich set of Pipelines for various use case scenarios
- In-memory pipelines for inline processing & high throughput message passing
- Inference pipelines for anomaly detection, classification and more
- Event-driven pipelines for topology updates, change detection and more
- Service pipelines for always-on data ingestion and Scheduled pipelines for timed data processing
- Action pipelines to trigger automations, Alerting pipelines for ticketing
Analyst Endorsed
- Gartner recently recognized Fabrix.ai Data Observability pipelines as a trusted vendor with Telemetry pipeline offering
