Executive Summary
Enterprise agents fail between demo and production. Fabrix.ai built the missing layer.
Most enterprise agent deployments stall between proof-of-concept and production — not because of model quality or prompting, but because agents lack the infrastructure to operate at scale. Real enterprise conditions break agents: massive data volumes, long-running multi-system workflows, autonomous execution, and governance requirements.
Fabrix.ai provides that infrastructure through these core capabilities:
Persistent, task-relevant context at scale - Large tool outputs, long conversations, and multi-step workflows don't overflow the LLM's context window. The Context Engine manages what agents remember and access, preserving coherence without bloat.
Agentic Data Federation - The Ontology Layer gives agents a living map of the enterprise data landscape. Encoded once, inherited by every agent automatically as sources evolve.
Hyperconnectivity - The Universal Tooling and Connectivity Engine connects any enterprise system, with or without native MCP support, while enabling direct data sharing between tools. Zero data shuttled through the LLM.
Full enterprise operational controls - Observability, cost tracking, scheduling, authorization, guardrails, human-in-the-loop approvals, and continuous quality improvement via AgentOps.
These capabilities are built on Fabrix.ai's tri-fabric platform, where data operations, automation, and AI share a common foundation, which is why they work together rather than alongside each other.
This is Agent Runtime Core - the operational layer between AI agents and enterprise systems. This whitepaper explains the architecture enterprise agents require, what it must provide, and how organizations can move to production systems that operate at scale with the observability, cost controls, and governance that enterprises demand.
1. The Enterprise Agent Gap: Why Production is Different
1.1 What Breaks in Production
AI agents have captured the imagination of every enterprise. The demos are compelling. An agent that can answer questions, execute tasks, and reason through problems looks like the future of work. Organizations rush to build proof-of-concepts, and many succeed. Agents work beautifully with curated datasets, controlled scenarios, and attentive human oversight.
Then they try to deploy to production.
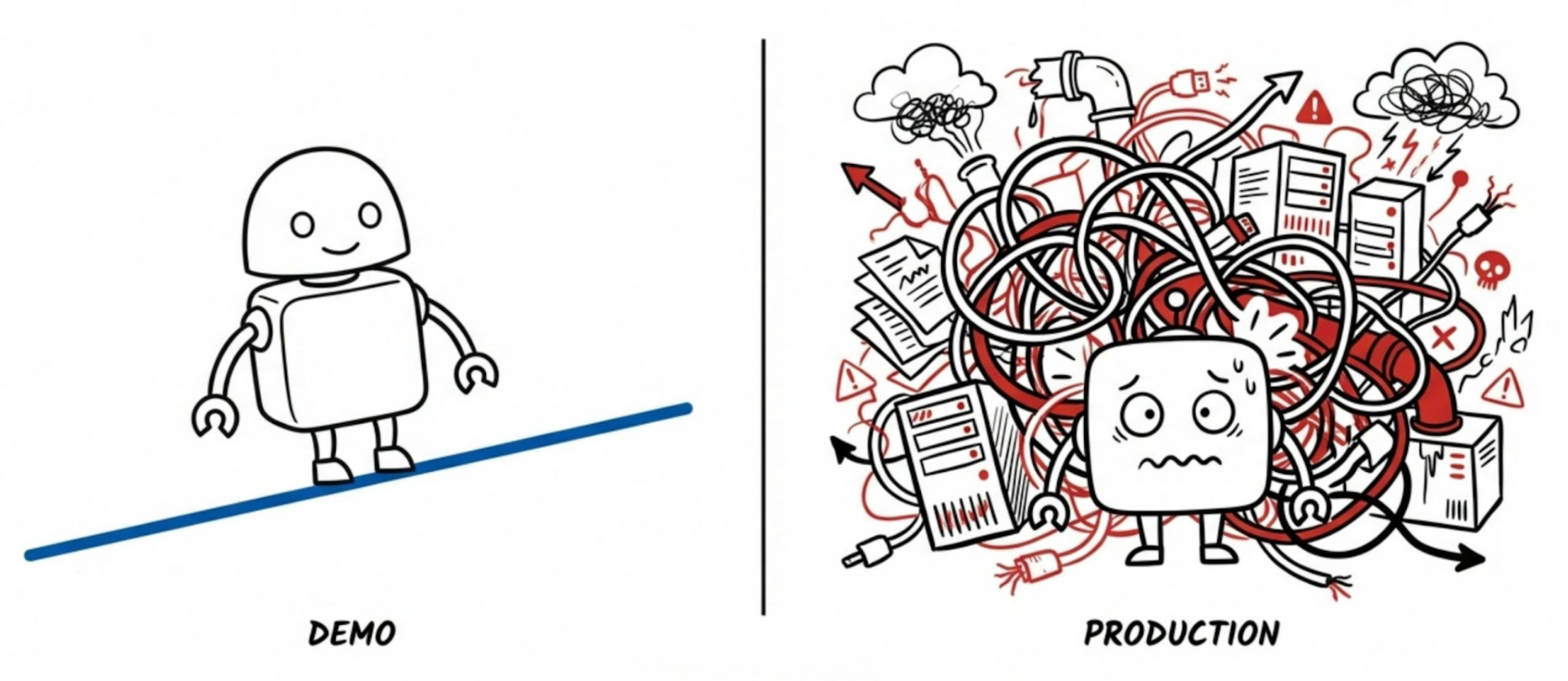
What happens? Agents that worked flawlessly in demos start failing. They choke on real data volumes (10,000-row datasets instead of 10-row examples). Long conversations become incoherent after 20+ turns. Coordinating across multiple enterprise systems proves impossible. There's no observability for production operations, no cost controls, no governance mechanisms. They can't be triggered automatically or integrated into existing workflows.
The pattern is clear: these aren't model failures or prompt engineering gaps. There's a missing architectural layer between agents and enterprise systems - something that manages context, coordinates tools, and provides operational controls. Without it, agents can't cross the gap from demo to production.
1.2 Why Enterprise Agents are Fundamentally Different
Enterprise agentic use cases are a different class of problem with different requirements.
Here's what changes when you move from prototype to production:
1.3 The Sixteen Production Challenges
We've worked with enterprises deploying agents at scale and seen sixteen specific challenges that only show up in production:
Context & Data Management:
- Tool Response Volume - Production tools return 10K+ rows that overflow context windows
- Tool Runtime Isolation - MCP servers can't communicate; LLM becomes expensive data shuttle
- Multi-Hop Reasoning Chains - Real tasks need 10-20+ sequential tool calls without losing coherence
- Fan-Out Operations - Enterprise operations touch 1000s of endpoints concurrently
- Conversational Context Decay - Long sessions lose track of referents and prior context
- Tool Proliferation - Dozens of available tools create cognitive overload
- Static Instruction Bloat - All instructions loaded regardless of relevance, with no principled basis for knowing which data sources or relationships matter for a given task.
Enterprise Operations:
- Observability Gap - No visibility into agent behavior at production scale
- Cost Visibility - Can't track or control spending across agents and users
- Agent Triggering - No built-in scheduling or event-driven execution
- Authorization - Can't enforce user-level permissions on agent actions
- Input Guardrails - No protection against malicious or inappropriate inputs
- Agent Lifecycle - No management of agents as versioned, governed entities
Infrastructure:
- Data Security - Enterprise data access without proper isolation and audit
- Multi-Tenancy - No separation between customers, departments, or projects
- Human-in-the-Loop - High-stakes operations need approval workflows
Every enterprise deployment hits these problems. Prompt engineering and fine-tuning won't solve them. You need architectural solutions.
1.4 Why Scaled-Up Prototypes Fail
Most agentic platforms started as frameworks that wrap LLM APIs with basic tooling. They work fine for demos because demos avoid the hard problems. Small datasets fit in context windows. Simple tool chains don't expose coordination issues. Short conversations don't reveal context management gaps. Developer oversight compensates for missing governance.
Scale exposes all of it. Try to handle 10,000-row tool outputs and the context window overflows. Need tools from different systems to share data? There's no mechanism. Conversations extending to 20+ turns lose coherence. Agents running autonomously have no observability or cost control.
These platforms treat enterprise requirements as features to add later, rather than recognizing them as a distinct architectural layer that must be carefully designed and built.
1.5 The Architecture Landscape
Several architectural patterns have emerged to address these challenges:
RAG + Orchestration: Vector databases with orchestration layers (LangChain, LlamaIndex) handle context overflow through retrieval. This works well for knowledge-heavy use cases but struggles with stateful multi-system workflows where tools need to coordinate in real-time.
State Machines + Supervisors: Explicit workflow graphs with supervisor agents provide predictability and observability. Effective for well-defined processes but brittle when workflows need to adapt dynamically based on intermediate results.
Microservices + Message Queues: Distributed tool execution with async messaging solves coordination and scale. Requires significant infrastructure investment and doesn't address the core LLM context management problem.
Each approach makes trade-offs. RAG systems require maintaining vector indices and retrieval relevance. State machines sacrifice flexibility for control. Microservices architectures demand orchestration expertise.
The integration problem remains: these solutions address individual challenges but require you to integrate context management, tool coordination, observability, and governance yourself. For enterprises without dedicated AI infrastructure teams, this integration tax is prohibitive.
What's needed is a purpose-built layer that sits between agents and enterprise systems - Agent Runtime Core that handles context, coordination, and operational controls as integrated capabilities rather than components you assemble yourself. Fabrix.ai built that layer.
2. Agent Runtime Core: the Enterprise Difference
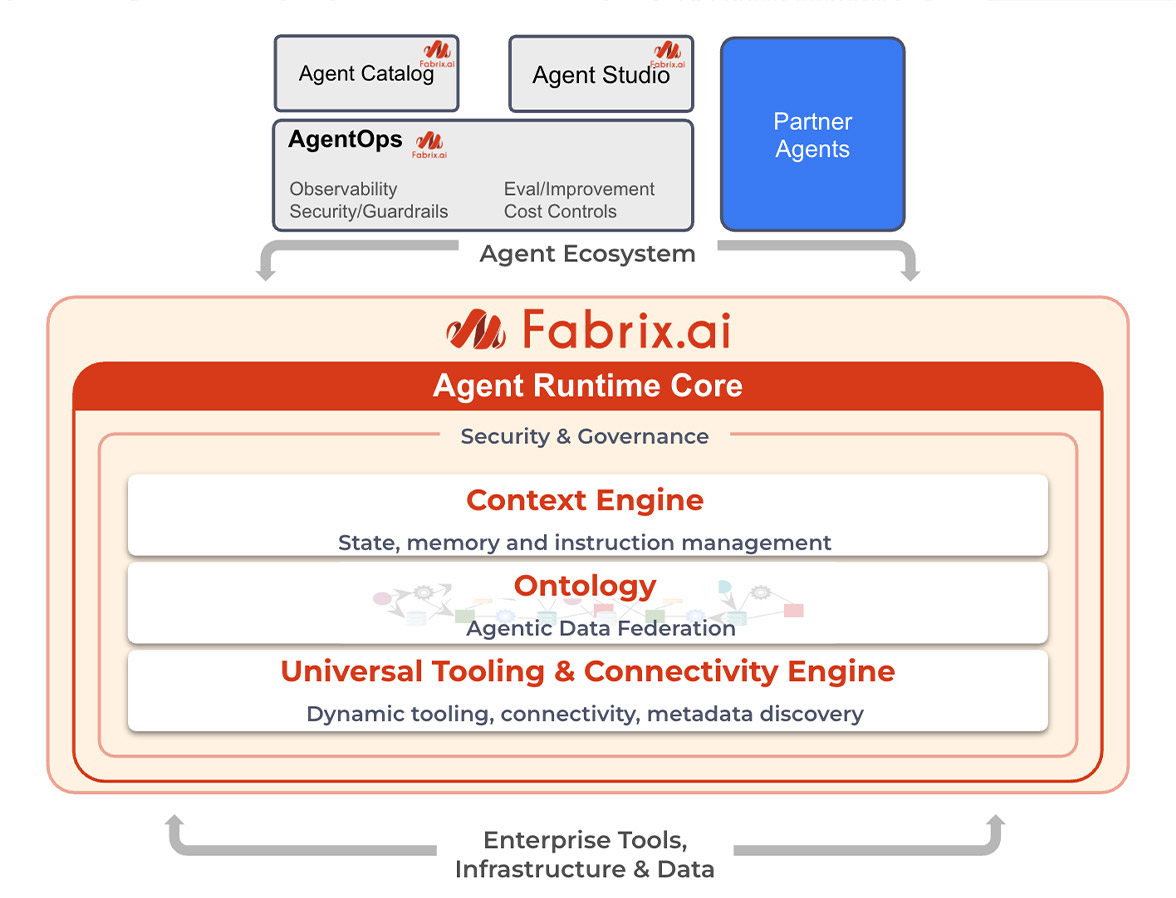
Fabrix.ai addresses these challenges through Agent Runtime - the operational layer between AI agents and enterprise systems. This runtime provides persistent context management, agentic data federation, and direct tool coordination: three foundational capabilities operating within a unified enterprise governance layer. Here's how:
2.1 The Context Engine
LLMs have fixed context windows. Enterprise workflows generate data and state that vastly exceeds those windows. Traditional approaches force everything through the LLM (tool outputs, conversation history, inter-tool communication), creating a bottleneck that leads to context overflow, massive token costs, coherence loss, and performance degradation.
But the deeper problem is context purity. The context window is the primary control mechanism for model behavior. Every token influences the probability distribution of what the model generates next. Fill the window with irrelevant data, stale conversation history, or unnecessary tool outputs, and you degrade output quality. The model has to sort through noise to find signal. Statistical probability suffers. You get worse answers, more hallucinations, less reliable tool use.
Managing context means precision. Give the model exactly the information it needs to generate the right output. Remove everything else.
Fabrix.ai's Context Engine solves this. It intelligently manages what agents remember and can access, keeping context relevant across long conversations and multi-tool workflows without overloading the LLM.
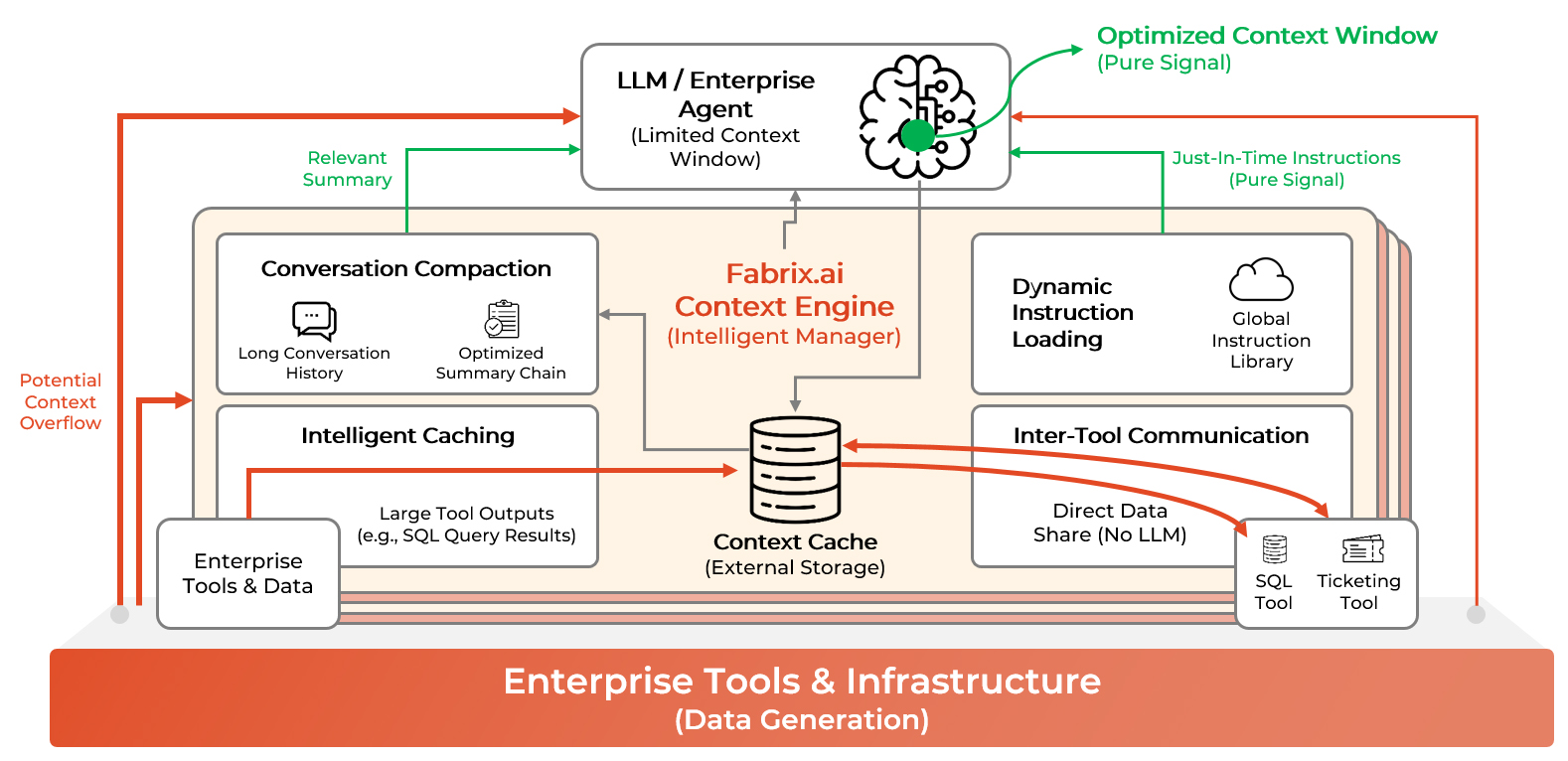
Here's how it works:
Intelligent Caching:
- Large tool outputs stored outside LLM context
- Agent receives summary + reference, not full content
- On-demand retrieval of specific sections
- Search, filter, and aggregate cached data without re-running tools
Inter-Tool Communication:
- Tools from different MCP servers share data directly
- Context cache acts as common memory plane
- No LLM mediation required for data passing
- Example: SQL query → cache → Ticketing tool reads directly
Conversation Compaction:
- Each turn generates summary optimized for current query
- Summary chain preserves salient facts from earlier turns
- Only relevant context enters LLM window
- Scales to unlimited conversation length
Dynamic Instruction Loading:
- Instructions loaded just-in-time based on user request
- Agent aware of available capabilities without loading all details
- Eliminates instruction bloat and cross-talk
- Supports specialized use cases without monolithic prompts
2.2 Agentic Data Federation with the Ontology Layer
Enterprise agents operating across multiple data sources face a curation problem: when an agent receives a task, how does the Context Engine know what information is actually relevant to put in front of the LLM? At small scale, this can be solved with hand-crafted prompt templates. At enterprise scale, with dozens of sources, inconsistent schemas, and constantly evolving data landscapes, that approach breaks down.
The Ontology Layer is the solution. It is a graph-based knowledge substrate, built prior to agent operation, that gives the Context Engine a principled, data-driven basis for making curation decisions. It encodes what data sources exist, what kinds of entities and attributes each source contains, and critically, how entities across sources relate to each other — for example, that a VM name in vCenter and a hostname field in Splunk refer to the same real-world object, and how to normalize between them.
When an agent receives a task, the Context Engine consults the ontology to determine which sources are relevant, which entities are involved, and what cross-source correlations should inform the agent's reasoning. This shapes what gets loaded into the LLM's context window — and equally importantly, what gets left out.
The ontology doesn't sit in the execution path. It functions more like a map than a middleware layer: built and maintained ahead of time, consulted at the moment curation decisions need to be made. As new sources are added or schemas evolve, the ontology is updated once and every downstream curation decision benefits automatically — without touching prompt templates or agent instructions.
The result is a Context Engine that makes smarter, more consistent relevance decisions at any scale.
2.3 Hyper-Connectivity with the Universal Tooling and Connectivity Engine
Enterprise agents need to work with the systems that exist today like SQL databases, ticketing platforms, monitoring tools, network devices, custom APIs, and legacy infrastructure. However many of these don't yet have native MCP support, and waiting for every vendor to implement MCP is a non-starter.
Even when external systems do have MCP support, each MCP server runs in its own isolated execution environment. Without a shared execution plane, the LLM shuttles data between isolated tools at massive token cost.
Fabrix.ai's Universal Tooling and Connectivity Engine solves both problems.
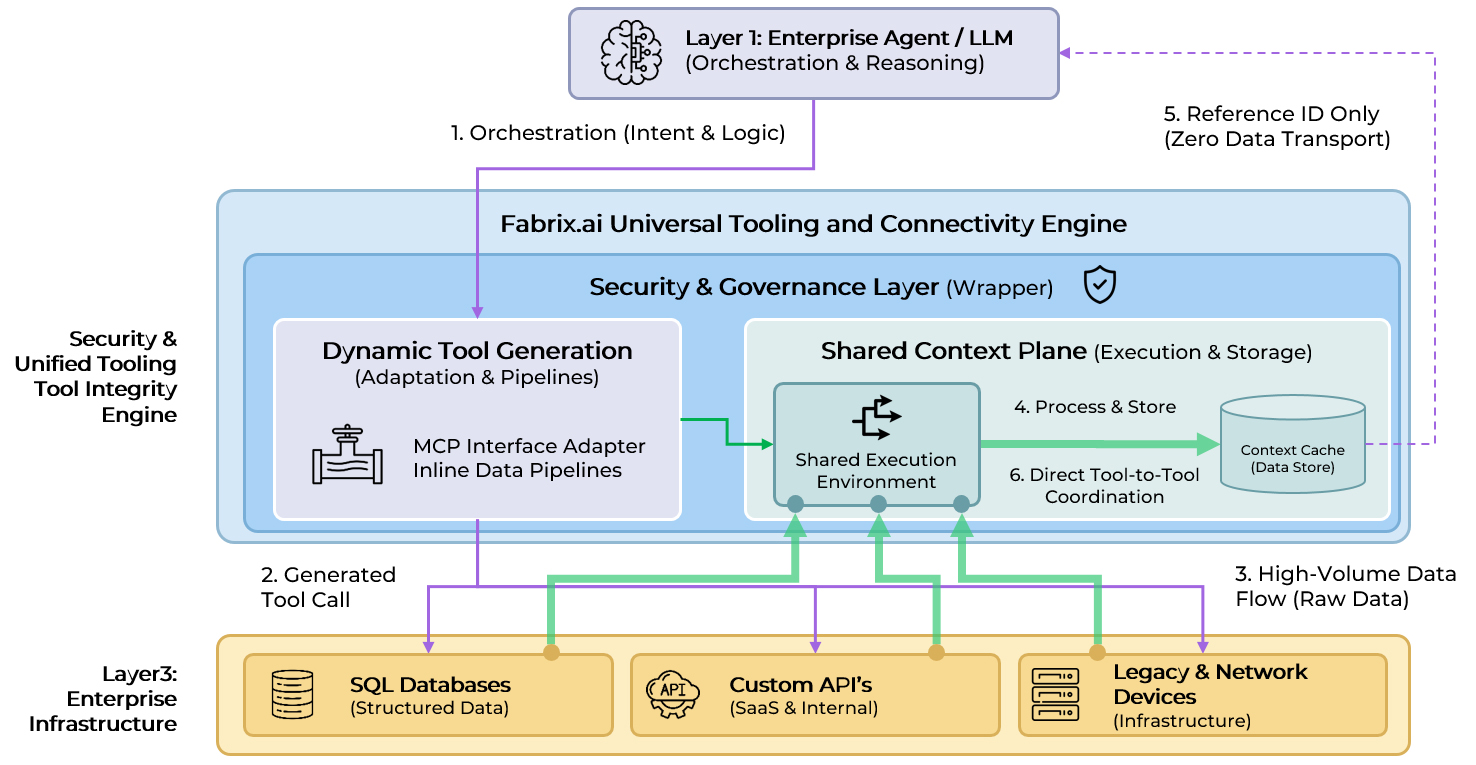
Dynamic MCP Tool Generation
The Tooling Engine eliminates the MCP adoption barrier by dynamically generating MCP-compatible tool interfaces for any enterprise system:
- Works with any system: Connects to APIs, databases, and proprietary systems whether they have native MCP support or not
- Leverages Data Fabric: Uses Fabrix.ai's Data Fabric to create agent-accessible tools from raw endpoints—no waiting for vendor MCP implementations
- Inline data pipelines: Complex multi-step operations embedded directly in tool definitions, leveraging distributed compute
- Dynamic at runtime: Tools created, modified, and deployed on-demand as enterprise needs evolve
Shared Context Plane for Direct Tool Coordination
Fabrix.ai's Universal Tooling and Connectivity Engine creates a shared context where tools from different systems communicate directly. It wraps raw MCP tools with semantic interfaces, manages credentials, enforces security, and validates parameters. Outputs are stored in the context cache with reference IDs returned to the agent. Subsequent tools read directly from cache. Zero data passes through the LLM.
The Shared Context Plane enables direct coordination not just between tools, but between specialized agents. One agent can execute a task and leave the results in the Context Cache for a follow-on agent to pick up, maintaining zero-data-transport efficiency across the entire multi-agent chain.
Dynamic Data Discovery
The system maintains awareness of what data exists where. Queries route to correct sources automatically. Agents reason about business problems, not data topology.
Multi-System Coordination
Network diagnostics query device status, pull configurations, check ticket history, and correlate logs. Each tool accesses prior outputs directly. The agent orchestrates without transporting data.
Security and Governance Layer
The Tooling Engine wraps all tools with enterprise-grade controls:
- Semantic abstraction: Raw tools wrapped with constrained, business-focused interfaces (e.g., "list_purchase_orders" instead of raw SQL)
- Security filtering: Row-level and column-level access controls enforced at execution
- Credential management: Centralized secrets management with least-privilege access
- Parameter validation: Type checking and input validation before execution
- Audit logging: Complete trace of tool calls, user identity, parameters, and results
- Query templating: Pre-tested, parameterized queries prevent injection attacks
2.4 The Tri-Fabric Architecture
The three main capabilities of Agent Runtime Core (persistent context, direct tool coordination, and enterprise operational controls) operate within Fabrix.ai's tri-fabric platform, where data operations, automation, and AI share a common foundation.
This integration is what makes reliable, secure and performant enterprise-grade agents possible. Most agent platforms bolt capabilities onto existing frameworks, creating integration gaps and operational brittleness. Fabrix.ai built these systems to work together from the ground up:
Data Fabric:
Composable "bots" for building data pipelines with distributed computing:
- Transport adapters, API connectors, data transformers
- ETL workflows for streaming, bulk, and batch processing
- Automatic concurrency and resource management
- Handles high-volume data operations at scale
Automation Fabric:
Post-processing, correlation, and workflow automation:
- Rule-based actions and event-driven triggers
- Policy enforcement and automated responses
- Scheduling and job orchestration
- Integration layer for enterprise systems
AI Fabric:
Agent Runtime Core leveraging Data and Automation capabilities:
- Context Engine for intelligent state management
- Universal Tooling and Connectivity Engine for tool abstraction and orchestration
- Tool handlers that invoke Data Fabric pipelines
- Continuous improvement system (AgentOps)
What this integration enables:
- Distributed Execution: Agent tools execute data pipelines across thousands of endpoints using Data Fabric's compute infrastructure
- Unified Context Across MCP Servers: Tools from different MCP servers communicate through shared context (detailed in section 2.3)
- Native Automation: Triggers and schedules are platform primitives integrated with observability
- Cross-Fabric Workflows: Agents invoke data processing and automation directly
- Agentic Data Federation: The Ontology Layer draws on Data Fabric's discovery capabilities to build and maintain a living map of the enterprise data landscape, giving every agent accurate knowledge of what data exists, where, and how it connects without manual maintenance.
Fabrix.ai's Agent Runtime Core isn't bolted onto agents as an afterthought. It's built on an integrated tri-fabric platform where data operations, automation, and AI work together from the ground up - which is why it can deliver capabilities that isolated agent frameworks can't.
3. Production-Grade Implementation
These three capabilities are delivered through four integrated systems.
3.1 Context Intelligence
Enterprise workflows generate far more data and state than fits in LLM context windows, yet agents need coherent access to information across tools, systems, and conversation turns.
Context & Cache Management
Large tool outputs are automatically managed:
- Tools configured to cache outputs exceeding size thresholds
- Agent receives metadata (row count, columns, summary) plus reference ID
- Full content lives in cache, not LLM context
- Agent can search, fetch sections, filter, aggregate, or parse cached data
- Example: 10,000-row SQL result cached; agent searches for specific values without re-querying database
Conversation Compactor
Multi-turn conversations maintain coherence without bloat:
- Each user query triggers generation of relevant summary from conversation history
- Summary optimized specifically for current query context
- Previous summaries accessible but not loaded unless relevant
- Agent always has targeted context, never bloated history
- Scales to virtually unlimited conversation lengths
The Universal Tooling and Connectivity Engine (architecture detailed in Section 2.3) ensures tools from different systems can leverage the Context Engine's shared cache. It wraps raw MCP tools with semantic interfaces, enforces security policies, manages credentials, and provides audit logging. This abstraction layer makes context sharing secure and governed.
Dynamic Instruction Loading (Prompt Templates)
Instructions loaded just-in-time:
- Agent lists available specialized instructions for every request
- Retrieves full instructions only when exact match to user query
- Maintains awareness of capabilities without loading all details
- Supports specialized use cases without monolithic prompts
- Persona-based access control for different user types
This is how Agent Runtime Core changes the game. Agents handle enterprise-scale data without context overflow. Token costs drop 5-10x by eliminating data shuttling. Coherence holds across 20+ turn conversations. Tool coordination works efficiently across heterogeneous systems.
3.2 Tool Ecosystem
The Challenge: Enterprise agents need access to dozens of tools across SQL databases, APIs, ticketing systems, monitoring platforms, and more. But exposing raw tools creates problems. The agent has to reason about too many options, many irrelevant to the current task. It wastes tokens describing unused tools. It selects the wrong tool or misuses powerful ones because the interfaces are too complex or poorly documented. Security becomes an issue when agents have unrestricted access to dangerous operations.
Fabrix.ai's Solution:
Tool Handler Architecture
Reusable primitives for rapid tool creation:
- Pre-built handlers: RunPipeline, StreamQuery, mcpWrapper, contextCache, template, webAccess, arangoDBPath, RESTAPI, splunk, dashboardManagement, and more
- Tools defined in YAML configuration—no coding required
- Consistent patterns for validation, templating, caching
- Non-technical admins can create domain-specific tools
MCP Wrapper Pattern
Abstract and constrain raw tools:
name: list_purchase_orders
type: mcpWrapper
credential: erp_system
mappedTo: executeQuery
parameters:
- name: status
type: enum
enum: [APPROVED, PENDING, REJECTED]
- name: date_range
type: objectUniversal Tooling and Connectivity Engine handles:
- Query construction from pre-tested templates
- Security filtering (row-level, column-level)
- Parameter validation
- Audit logging
Result: Agent calls constrained, semantic tool instead of constructing raw SQL
Inline Data Pipelines
Complex processing embedded in tool definitions:
name: dataset_to_splunk
type: runPipelineToolV2
pipeline_content:
template_type: jinja
template: |
@c:new-block
--> @dm:recall name='{{source_document}}'
--> @dm:fixnull-regex
--> @splunkv2:add-to-index index='{{splunk_index_name}}' & create='true'
parameters:
- name: source_document
type: string
description: Document name in context cache or dataset
required: true
- name: splunk_index_name
type: string
description: Index name at Splunk to be saved as
required: trueThis tool:
- Retrieves a dataset from context cache
- Cleans null values
- Writes to Splunk index using Data Fabric's distributed compute
- All without custom code
The results: Tools defined in minutes using YAML instead of weeks of coding. Raw operations wrapped with business-focused interfaces. Fan-out operations leverage Data Fabric's distributed execution. Project admins create tools without needing developers.
3.3 Enterprise Operations
Production agents need scheduling, triggering, lifecycle management, authorization, observability, cost controls, guardrails, and approval workflows.
Observability
Complete visibility into agent behavior:
- Every conversation fully captured: messages, tool calls, results, timestamps
- Token usage and dollar costs per session
- All artifacts preserved (cache documents, dashboards)
- Unified platform view (no external tools required)
- Automated quality evaluation and continuous improvement (detailed in section 3.4)
Cost Tracking & Control
Financial visibility and spending governance:
- Real-time cost dashboards with breakdown by agent, user, project, session
- Automatic token-to-dollar conversion
- Multi-level quotas: global, project, user group, individual
- Warning thresholds and blocking when limits exceeded
- Finance and engineering speak same language
Agent Lifecycle Management
Agents as governed entities:
- Centralized agent catalog with search and discovery
- Project-based organization with dev/prod separation
- Import/export for version control and portability
- Access control via project membership
- Resource sharing: tools, personas, templates reused across projects
- Users see only agents for their authorized projects
Multi-Agent Orchestration and Observability
- Orchestration & Handoff: Support for supervisor-subordinate patterns or peer-to-peer handoffs
- Unified Observability: Trace a single user request as it moves through multiple agents, viewing the combined cost and performance metrics in one view.
Agent Triggering & Automation
Scheduling and event-driven execution:
- Cron-style scheduling for periodic runs
- Event triggers (ticket created, threshold breached, deployment completed)
- Full management UI for trigger configuration
- Observability integration—all triggered runs logged
- Automation Fabric integration for complex workflows
Authorization & Access Control
Enterprise-grade permissions:
- Project membership controls agent access
- Role-based permissions (viewer, operator, admin)
- Users only invoke agents they're authorized for
- Audit trails capture user identity for all actions
- Separates user permissions from agent capabilities
Input Guardrails & Safety
Protection against malicious inputs:
- Configurable guardrail models per agent
- Pre-configured options plus bring-your-own
- Automatic injection—configured once at agent creation
- Detects: prompt injection, policy violations, PII, inappropriate requests
- Blocks violating requests before consuming tokens
Human-in-the-Loop Workflows
Approval mechanisms for high-stakes operations:
- Agents request approval before sensitive actions
- Approval requests embedded in application workflows
- Full context provided for informed decisions
- Audit trail of who approved what and when
- Example: RCA agent diagnoses issue → creates approval request → user reviews → remediation executes if approved
Multi-Tenancy & Isolation
Native multi-tenant architecture:
- Complete data separation per tenant
- Shared infrastructure with security boundaries
- Tenant-specific configurations and policies
- Safe for SaaS deployments or departmental separation
You get production-grade operations from day one. Agents improve automatically based on usage patterns. Financial accountability with granular cost tracking. Governance, security, and compliance all built-in. No bolt-on tools required; everything's integrated.
3.4 Continuous Improvement (AgentOps)
Why This Matters:
Most platforms stop at logs and dashboards showing "what happened." Fabrix.ai provides a closed-loop system that systematically improves agent quality over time: AgentOps as a discipline.
The Improvement Loop:
Production Usage → Automated Evaluation → Drift Detection
↑ ↓
Impact Validation ← Testing ← Approval ← Prescriptive ProposalHow It Works:
- Hourly Evaluation: Every conversation automatically evaluated for quality dimensions (helpfulness, accuracy, clarity), tool success rates, knowledge gaps, user ratings
- Daily Drift Detection: Automated analysis identifies degradation:
- Dimension scores dropping
- Tool failure rates increasing
- Rating declines
- Negative outcome shifts
- Improvement Extraction: System prescribes specific fixes:
- "Add instruction clause for X scenario"
- "Clarify tool Y parameter requirements"
- "Fix validation in tool Z"
- "Expose data source A"
- "Adjust persona constraint B"
- Weekly Aggregation: Related events grouped into proposals with:
- Exact text to add/modify/remove
- Before/after examples from real conversations
- Expected metric improvements
- Implementation steps
- Admin Governance: Review, approve, modify, or reject proposals
- Automated Validation: Tests run post-change; metrics tracked to confirm improvement
- Test Gap Analysis: System identifies missing test coverage and proposes new tests based on actual failures
Key Differentiators:
- Prescriptive, not descriptive: System tells you exactly what to fix and how
- Evidence-based: Every proposal backed by actual conversation failures
- Automated: Runs continuously without manual intervention
- Validated: Changes tested before declaring success
- Closed-loop: Impact measured against expected improvements
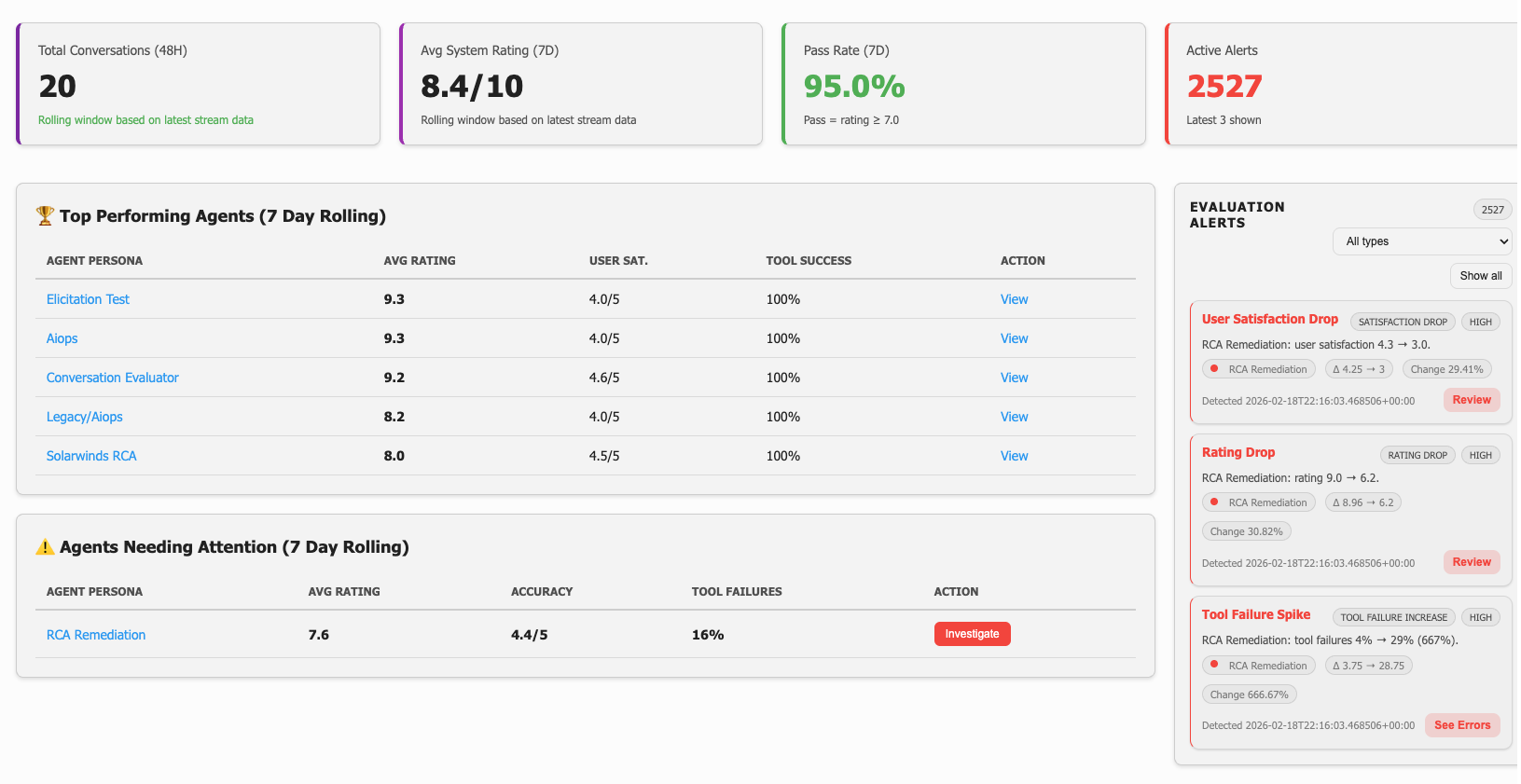
Success Metrics:
- Time from issue detection to resolution: <7 days
- Improvement acceptance rate: >70%
- Sustained dimension scores: >4.0
- Tool failure rates: <5%
- User satisfaction: >4.5
This is what separates experimental agents from production systems that get better over time.
4. What to Ask When Evaluating Enterprise Agent Platforms
Use this checklist when evaluating platforms for production agent deployments. These questions separate platforms built for enterprise scale from those designed for demos.
Context Management
How do you handle large tool outputs?
- Can your platform cache tool outputs outside the LLM context window?
- How does the agent access cached data without re-running expensive operations?
- What happens when a tool returns 10,000 rows?
How do you maintain context across long conversations?
- What's your strategy for 20+ turn diagnostic sessions?
- How do you prevent context window bloat while preserving critical information?
- Can you show me how conversation history is managed and summarized?
How do you ensure context purity?
- How do you prevent irrelevant data from diluting the model's context window?
- What mechanisms exist to give the model exactly what it needs and nothing else?
Tool Integration & Coordination
How do tools from different systems communicate?
- If I have a SQL MCP server and a Ticketing MCP server, can they share data directly?
- Or does the LLM have to shuttle data between isolated runtime environments?
- Show me an example of a multi-system workflow.
How do you handle tool abstraction?
- Can I wrap raw SQL or API tools with constrained, business-focused interfaces?
- How do you prevent agents from having unrestricted access to dangerous operations?
- Can non-technical admins create tools without writing code?
What about fan-out operations?
- How do you handle operations that touch 1000+ endpoints concurrently?
- What happens when some endpoints fail in a large-scale operation?
- Show me how your platform manages distributed execution.
Enterprise Operations
What observability do you provide?
- Can I see every tool call, token count, and cost for every session?
- Is observability integrated or do I need separate tools?
- How do I know if my agents are achieving their goals?
How do you handle cost control?
- Can I set spending limits at the global, project, or user level?
- Do you convert tokens to actual dollars automatically?
- What happens when an agent approaches its budget limit?
What about agent lifecycle management?
- How do I manage multiple agents across dev and prod environments?
- Can I version agents and roll back changes?
- How do users discover which agents they have access to?
Do you support automated triggers?
- Can agents run on schedules or in response to events?
- Are triggered executions tracked in your observability system?
- Show me how you handle event-driven agent execution.
How does authorization work?
- Can I enforce user-level permissions on what agents can do?
- How do you prevent agents from becoming privilege escalation vectors?
- What's the audit trail for agent actions?
What guardrails exist?
- How do you protect against prompt injection or malicious inputs?
- Can I configure different guardrail models per agent?
- Are guardrails applied before the agent consumes tokens?
Continuous Improvement
How do you detect quality degradation?
- Do you automatically evaluate agent performance?
- How do you identify when agents start failing more often?
- Can you detect drift in real-time?
What happens when quality drops?
- Do you just show me metrics, or do you tell me what to fix?
- Can your system generate specific, prescriptive improvement proposals?
- Show me an example of an improvement recommendation.
How do you validate changes?
- Do you have automated testing for agents?
- Can you measure whether a change actually improved quality?
- What's your rollback strategy if something breaks?
Architecture & Integration
What's your architecture for scale?
- How do you handle the gap between demo performance and production reality?
- What changes when you go from 10 users to 10,000 users?
- Are enterprise features built-in or bolted on later?
How do you integrate with our existing systems?
- What's your approach to multi-tenancy?
- Can you work with our on-premises infrastructure?
- How do you handle data security and compliance requirements?
5. Conclusion
The enterprise agent opportunity is real. Organizations that successfully deploy agents at production scale will gain significant competitive advantages in operational efficiency, cost optimization, and decision velocity.
But success requires the right architecture. The gap between demo and production is an architectural problem, not a scaling problem. Agents need infrastructure that manages context intelligently, coordinates tools efficiently, operates autonomously with governance, and improves continuously based on real usage.
Fabrix.ai provides that Agent Runtime Core: a Context Engine that keeps agents from choking on real data and losing their train of thought, an Ontology Layer that gives agents a living map of the data landscape, a Universal Tooling and Connectivity Engine that enables direct cross-system coordination, a tri-fabric platform foundation, and AgentOps discipline that treats agent quality as a production concern with continuous improvement.
This is the architecture enterprise agents actually need to deliver lasting value.
About Fabrix.ai
Fabrix.ai is the enterprise agentic operational intelligence platform for ITOps, NOCOps, and AIOps. Our tri-fabric architecture enables the Agent Runtime Core that enterprise agents need to operate at production scale with the observability, governance, and continuous improvement that enterprises demand.
For more information, visit fabrix.ai or contact us at info@fabrix.ai.