
NVIDIA
Integration Ready
Fabrix.ai integrates with your NVIDIA GPU infrastructure as the inference layer for AI agents. Whether you use NVIDIA NIM microservices or an open-source model-serving stack - on bare metal, private cloud, or NVIDIA-hosted cloud endpoints - Fabrix.ai agents connect to those LLM endpoints natively, so you get full agentic AI powered by the GPU infrastructure you already own.
Integration Highlights
Fabrix.ai runs on standard CPU infrastructure. The NVIDIA integration is specifically about the inference layer — connecting Fabrix.ai agents to GPU-hosted LLM endpoints, wherever those endpoints live.
Your NVIDIA infrastructure hosts LLM endpoints
NVIDIA GPUs on-premises, in a private cloud, or via NVIDIA-hosted cloud endpoints serve language models for inference. This can be via NVIDIA NIM microservices (Path A) or an open-source stack (Path B) — details below.
With NVIDIA NIM Microservices
Ideal for enterprises prioritising a fully managed, optimised inference stack with NVIDIA enterprise support and guaranteed SLAs.
With Fabrix.ai-Assisted Install
Ideal for teams with in-house infrastructure expertise who want full control, model flexibility, and maximum return on their NVIDIA GPU investment.
NIM microservices for
Open-source stack for
Fabrix.ai agents investigate, reason, and act — powered by your NVIDIA infrastructure
The Enterprise Knowledge Graph, agentic data federation, AgentOps observability, and all other Fabrix.ai capabilities operate normally — now with GPU-accelerated inference giving your agents faster, more capable reasoning at every step.
Typical Models on NVIDIA Infrastructure
Fabrix.ai connects to any model served via a compatible endpoint on your NVIDIA stack — NIM-managed or open-source. Below are examples commonly deployed with Fabrix.ai for IT operations use cases.
NVIDIA Nemotron Family
Open-Source Models (via vLLM or NIM)
Models are selected and validated per deployment based on your use case, hardware specifications, and inference performance requirements.
Real-World Deployment
Production-Grade Results on NVIDIA Hardware
A large Telco customer procured NVIDIA L40S GPUs on bare-metal servers and worked with Fabrix.ai to deploy an open-source LLM stack — without any NIM licensing costs. Full data sovereignty, production-grade agent quality.
What You Get From This Integration
Whether you use NIM or the open-source path, the outcome is the same — agentic AI on your infrastructure, on your terms.
Complete Data Sovereignty
Inference stays inside your environment. No data sent to external cloud LLM APIs — your IT telemetry, logs, and operational data never leave your infrastructure.
GPU-Accelerated Agent Reasoning
NVIDIA GPU acceleration dramatically reduces inference latency — agents investigate incidents, correlate events, and produce reasoning faster than CPU-only or shared cloud endpoints.
Maximize Your NVIDIA Investment
GPU hardware you've already procured — for training, simulation, or other AI workloads — can now serve as the inference backbone for your entire IT operation agent fleet.
Full Model Flexibility
Choose the model that fits your use case — Nemotron for agentic reasoning, Llama or Mistral for general intelligence, or GPT-OSS equivalents proven to deliver commercial-grade results at open-source cost.
Deploy Anywhere
On-premises bare metal, private cloud, hosted private cloud, or NVIDIA-hosted public cloud endpoints. The integration works the same way regardless of where the GPUs live.
Full AgentOps Visibility
Fabrix.ai's AI Observability layer traces every inference call, token cost, and model decision — so you have complete visibility into what your agents are doing on your NVIDIA infrastructure.
How Fabrix.ai Connects to Your NVIDIA Stack
Whether your endpoints run via NIM microservices or an open-source vLLM stack — Fabrix.ai agents connect, reason, and act across your entire IT environment.
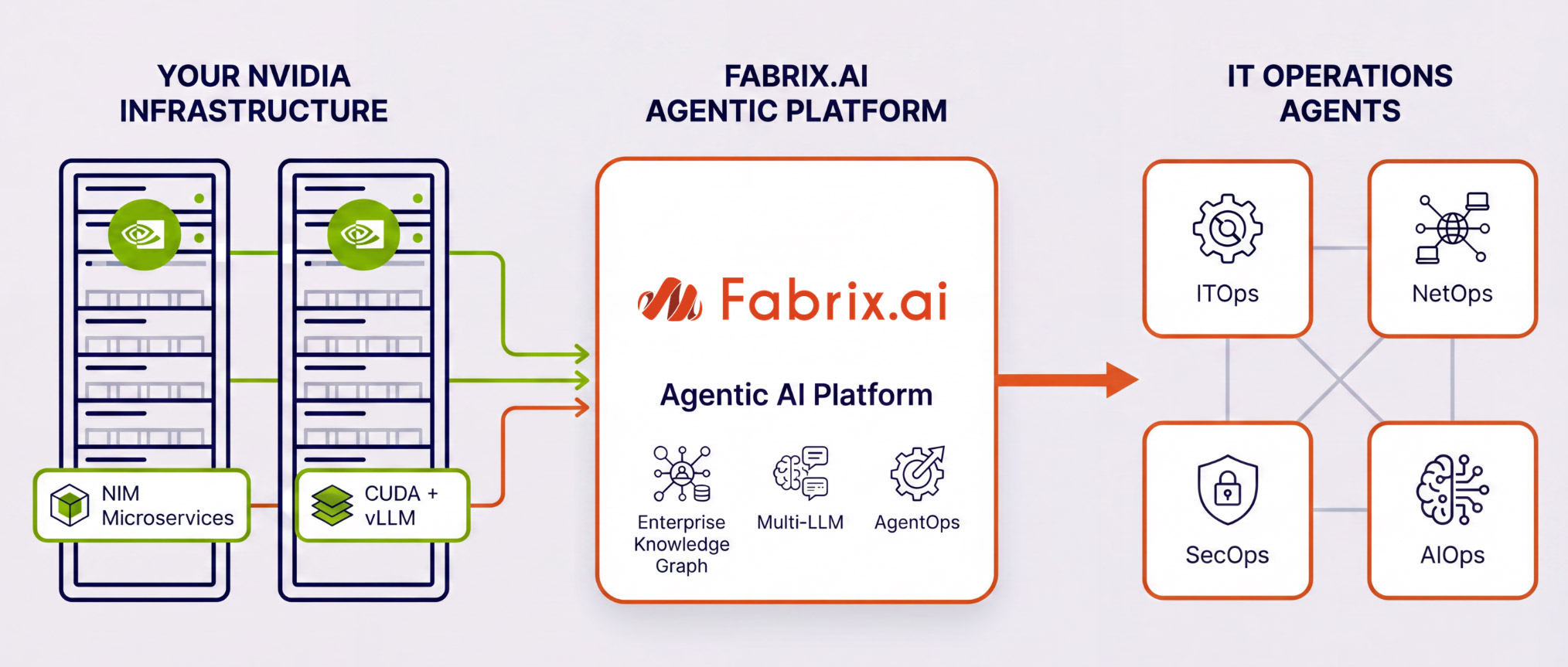
Fabrix.ai Agentic Platform connects to GPU-hosted LLM endpoints — on-prem, private cloud, or NVIDIA cloud — to power AI agents for IT operations.
Get Started
Start Your Agentic Journey with NVIDIA Infrastructure
Talk to our team about your NVIDIA environment — GPU model, deployment type, and the models you want to use. We'll walk you through the integration options and validate the right configuration for your IT operations use case.
On-prem · Private cloud · NVIDIA-hosted cloud · NIM or open-source · Any compatible LLM endpoint